
Список виборців Індії: ETL з перевіркою даних та транслітерацією
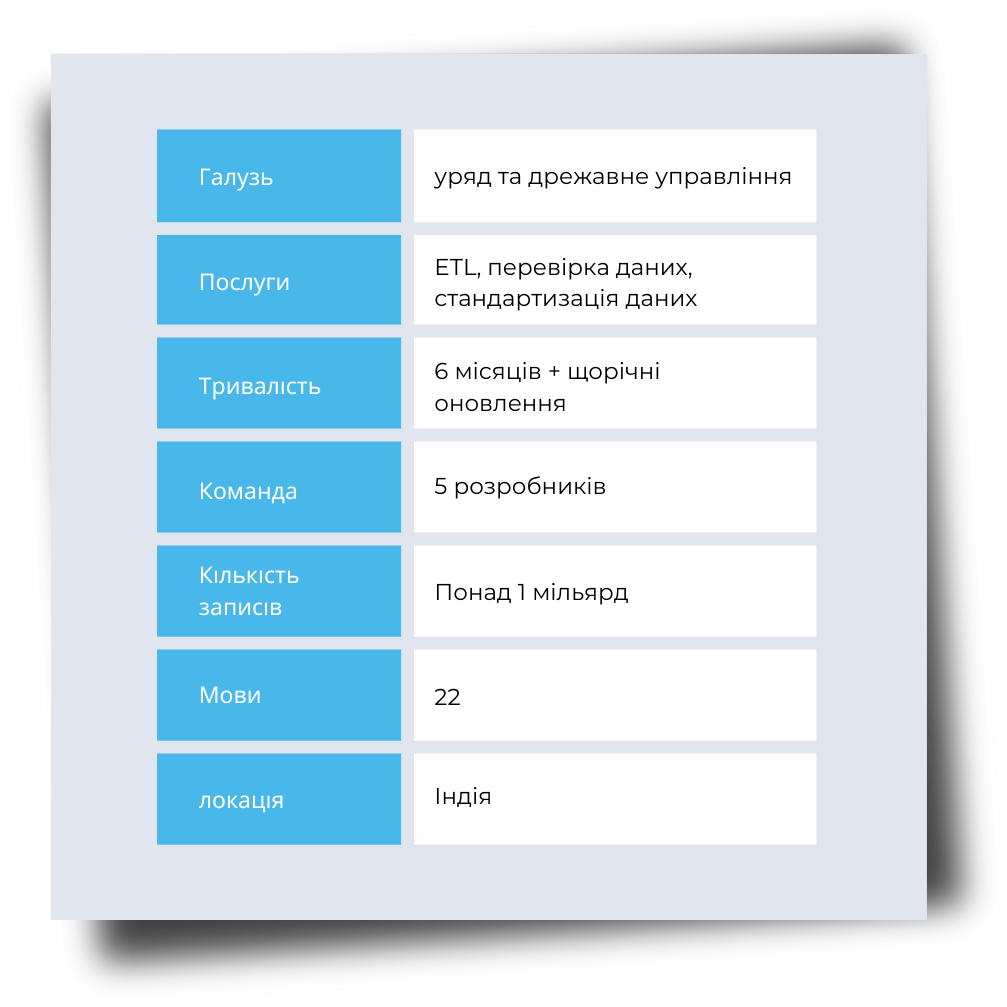
Компанія Apriori Data звернулася до нас із завданням зібрати список виборців з усієї Індії. Клієнту потрібні були дані з кожного штату і адміністративного підрозділу. Нам потрібно було не просто зібрати, а й очистити, стандартизувати та перевірити ці дані, звіряючи їх з інформацією з India Post.
Оскільки дані в реєстрах були доступні на 22 різних мовах, нам довелося також зробити їхню транслітерацію на англійську. Завдання полягало в тому, щоб усе це об’єднати в один файл, який можна було б легко оновлювати щороку.
Виклики проєкту зі списком виборців в Індії

Обробка 1 мільярда записів — це серйозний виклик. Для цього потрібна серйозна обчислювальна потужність і багато місця для зберігання. Крім того, ми мали зробити так, щоб дані швидко витягувалися, оновлення проходили без збоїв, і вся інформація була повною.
Ми зіткнулися з даними, які були в різних форматах і на різних мовах. Більшість записів були в PDF, але також були фотографії рукописних виборчих форм, написаних мовами, з якими звичайні OCR-інструменти не справляються.
Щоб переконатися в точності даних, ми звіряли інформацію від виборчих органів Індії із записами з India Post. Перевірка імен і адрес виборців виявилася досить непростою через різні формати й структури даних.
Ми працювали з даними виборців на 22 мовах, кожна з яких специфічна для різних штатів і територій Індії. Найбільші складнощі були з Пенджабом, бо OCR не могли розпізнати текст на зображеннях. Ми зберегли оригінальну мову, але також переклали дані на латиницю. Цей процес вимагав лінгвістичних знань та складних алгоритмів транслітерації.
Як ми зібрали онлайн-список виборців Індії
Збір даних
Ми розробили спеціальні модулі, щоб зібрати списки виборців з NVSP Індії у форматі PDF і зображень від виборчих органів по всій країні.
Навчання машин
Ми співпрацювали з лінгвістами, щоб створити алгоритми, які навчили наші машини розуміти та обробляти 22 індійські мови.
Витяг даних
Ми написали код для витягування даних з PDF і використали OCR-технологію для отримання інформації з зображень виборчих форм.
Стандартизація даних
Після витягнення даних ми їх очистили, стандартизували і транслітерували, щоб все було в єдиному форматі.
Перевірка даних
Щоб переконатися в точності інформації, ми звірили стандартизовані дані з іменами та адресами з India Post.
Щорічні оновлення
Ми слідкуємо за оновленням списків виборців і вносимо зміни в базу, щоб включити останню інформацію від виборчих органів та India Post.
Технології, які ми використовували в проєкті

AWS

.NET

Tesseract OCR
Результати проєкту зі збору даних про виборців Індії
Наш клієнт тепер має централізовану цифрову базу даних виборців Індії, яка містить понад один мільярд записів з 36 джерел. Дані доступні як рідними мовами, так і в транслітерації на англійську. Цей файл включає 63 повністю перевірені та нормалізовані поля даних:
- Ім'я виборця
- Ім'я родича
- EPIC номер
- Адреса
- Вік
- Стать
- Рік народження
- Рік перегляду виборчого списку
- Назва виборчої дільниці

Перетворіть великі дані на ваші можливості
Зв'яжіться з нами сьогодні. Ми розглянемо ваш проєкт, надамо індивідуальне рішення та кошторис, і почнемо працювати, як тільки ви погодитесь.
Зв'яжіться з нами
Заповніть форму з проєктними даними, щоб ми могли запропонувати вам персоналізоване рішення.



